
Data Augmentation to break Feedback Loops
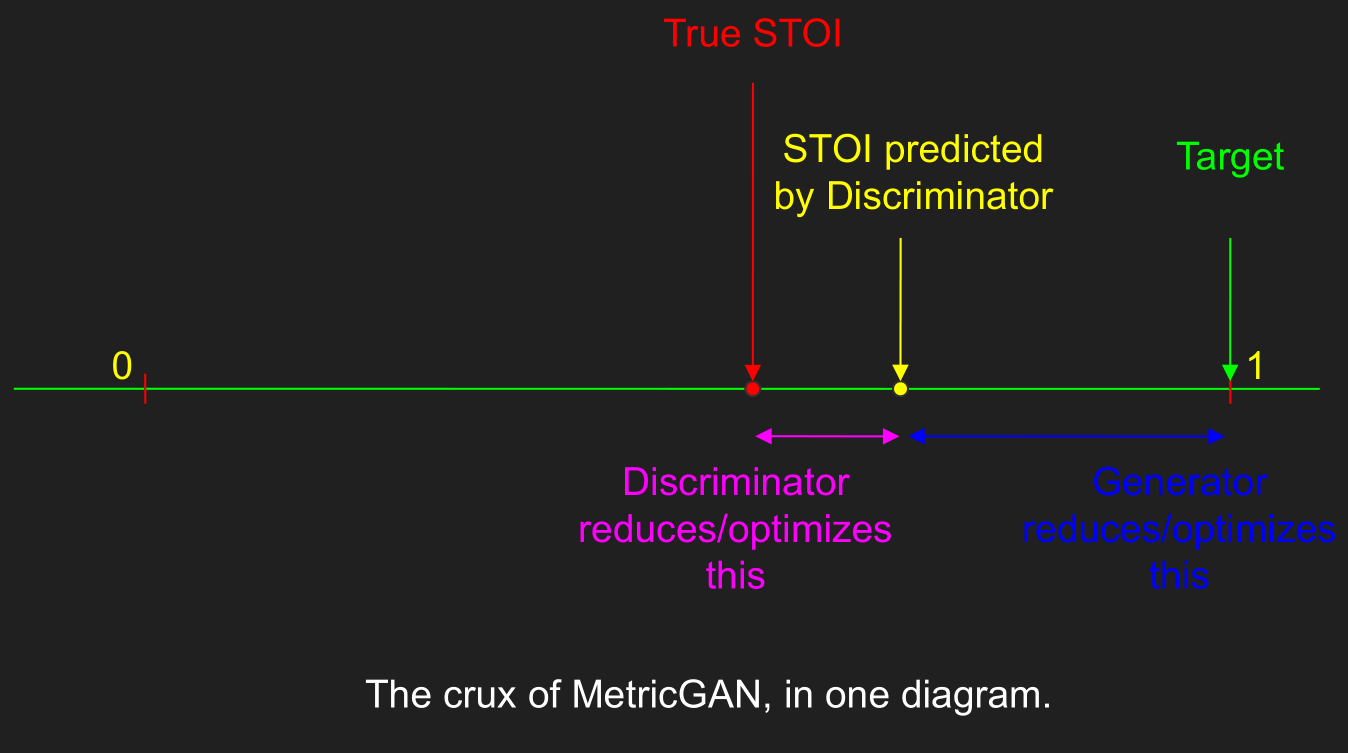
MetricGAN (ICML 2019) is a clever twist on GANs used to denoise speech. In particular, it uses a Discriminator to approximate a non-differentiable objective like Short-Term Speech Intelligibility (STOI), then backpropagates the objective to train a Generator to achieve high scores. The Generator and Discriminator are updated alternatingly. This allows optimization of non-differentiable metrics. In this project, I characterized MetricGANs in detail and found that they are much harder to train than GANs. The culprit is a common feedback loop - the Generator starts off being terrible, and the Discriminator overfits to the terrible outputs, giving only low scores. The Generator mis-optimizes this overfitted objective and becomes worse. The cycle continues. An effective and elegant way to solve this is to sneakily introduce high-quality (low-noise) audio samples along with the Generator outputs at times, so that the Discriminator doesn’t get used to the initally bad outputs. Incidentally, such data augmentation also helps generalization - the trained model generalized extremely well to removing background music, despite the training data only having non-music sounds (buses, people talking, and so on). You can find my code on GitHub.